Azure Batch to handle embarrassingly parallel machine learning workload
Azure Batch
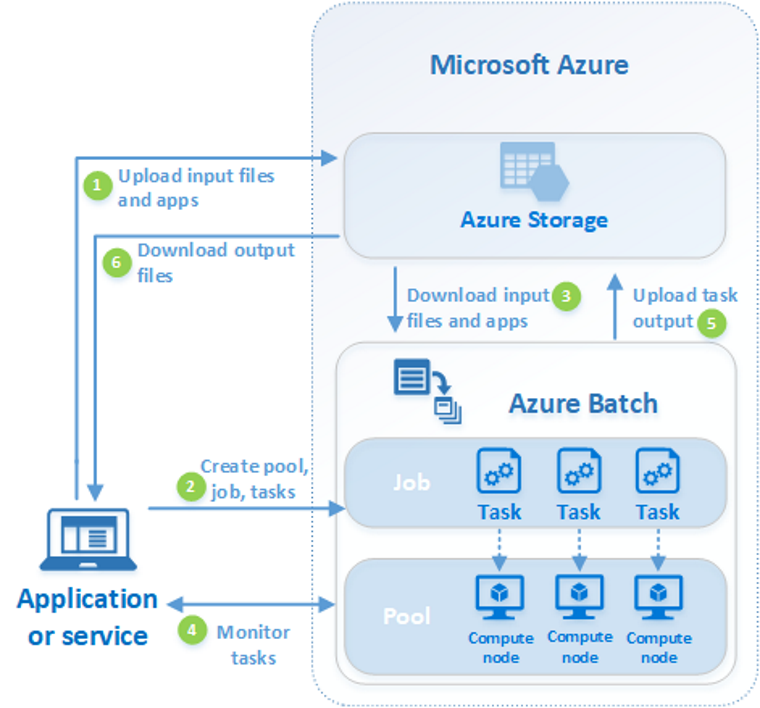
Azure Batch service provides a way to handle embarrassingly parallel machine learning workload with a minimum effort.
What’s embarrassingly parallel?
Parallel computing, a paradigm in computing which has multiple tasks running simultaneously, might contain what is known as an embarrassingly parallel workload or problem (also called perfectly parallel, delightfully parallel or pleasingly parallel). An embarrassingly parallel task can be considered a trivial case - little or no manipulation is needed to separate the problem into a number of parallel tasks. This is often the case where there is little or no dependency or need for communication between those parallel tasks, or for results between them.
What’s Azure Batch?
Use Azure Batch to run large-scale parallel and high-performance computing (HPC) batch jobs efficiently in Azure. Azure Batch creates and manages a pool of compute nodes (virtual machines), installs the applications you want to run, and schedules jobs to run on the nodes. There’s no cluster or job scheduler software to install, manage, or scale. Instead, you use Batch APIs and tools, command-line scripts, or the Azure portal to configure, manage, and monitor your jobs.
Set up Azure batch
Follow the steps: Run a Batch job - Python
Basically you need to create:
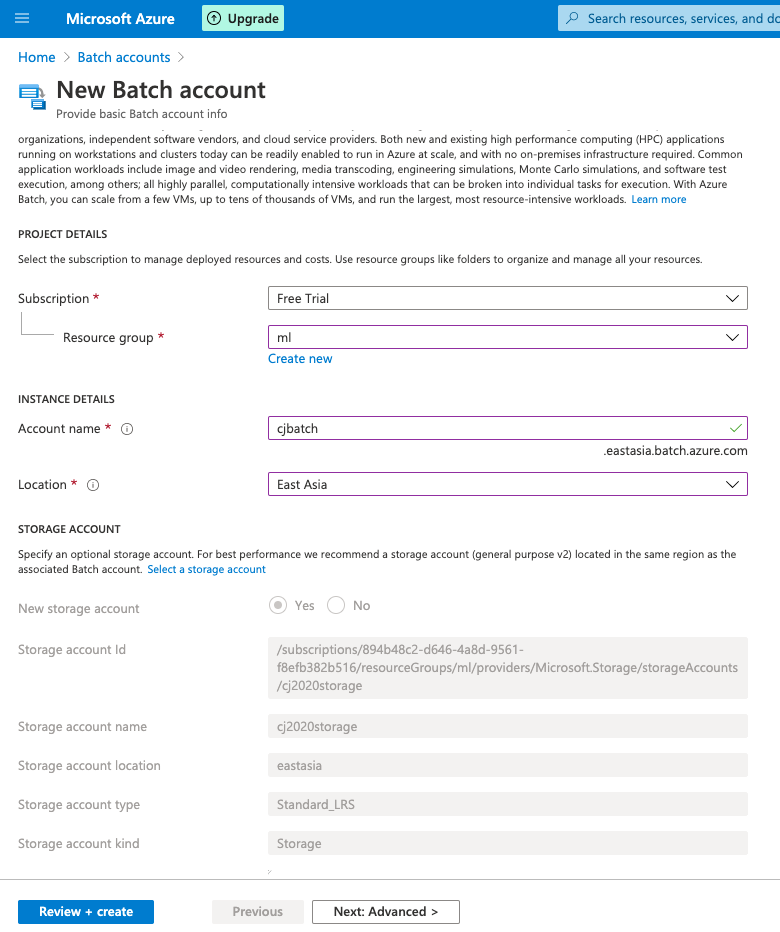
- A Batch account
- A linked Azure Storage account
A machine learning example
The codes can be found:
git clone git@github.com:abinitio888/azure_batch.git
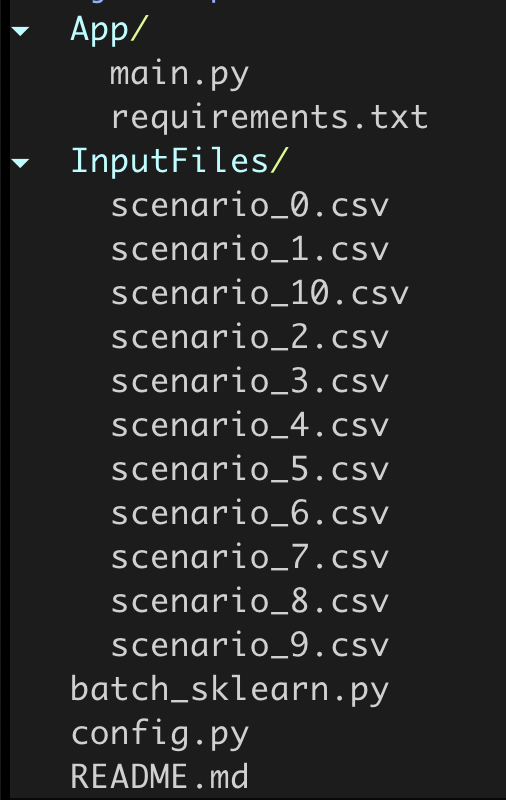
Codebase skeleton.
Appfolder contains the machine learning codes.InputsFilesfolder contains the input data for each scenario.batch_sklearn.pyis the Batch API code to control the Batch services.config.pycontains the secrets to Batch.
Main application. Under the App folder, a machine learning solution can be structured.
# main.py
import argparse
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="App main entry")
parser.add_argument("input_path", type=str, help="Job input path")
parser.add_argument("output_path", type=str, help="Job output path")
args = parser.parse_args()
fd = open(args.input_path)
df = pd.read_csv(fd, index_col=0)
X = df.iloc[:, :-1]
y = df.iloc[:, -1]
clf = RandomForestClassifier(n_estimators=10, max_depth=None,
min_samples_split=2, random_state=0)
scores = cross_val_score(clf, X, y, cv=5)
mean_score = scores.mean()
with open(args.output_path, "w") as fd:
fd.write(f"The model score: {mean_score}")
Install the package dependence. The package dependence can be installed in the batch_sklearn.py with requirements.txt.
# batch_sklearn.py
command = "/bin/bash -c \""\
"python3.7 -m pip install --upgrade pip && "\
f"python3.7 -m pip install -r {config._APP_PATH}/requirements.txt && "\
f"python3.7 {config._APP_MAIN_SCRIPT} {input_file_path} {output_file_path}"\
"\""
Run the example
Kick off script. The batch_sklearn.py provides step-wise instructions to control the Azure Batch job.
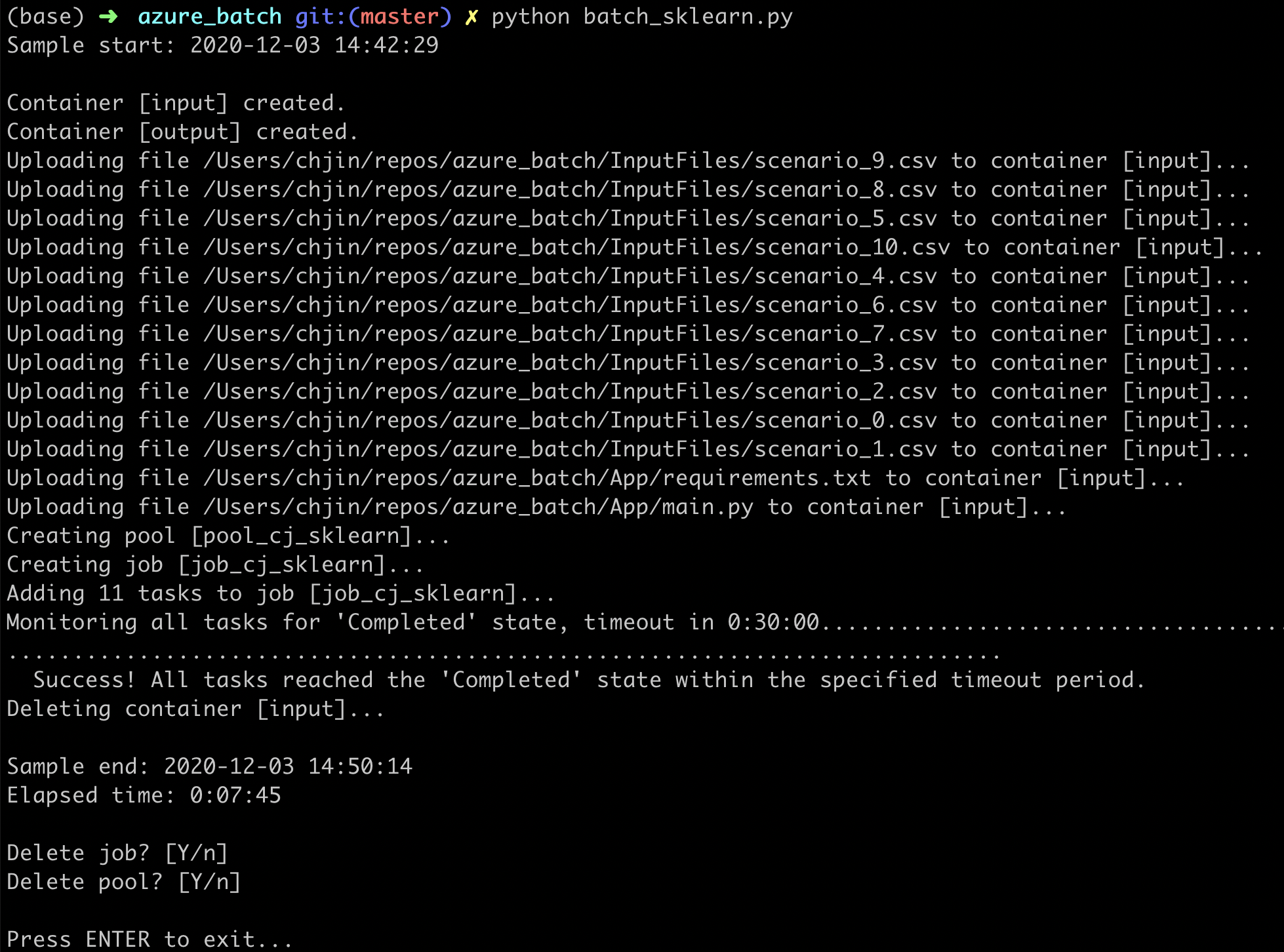
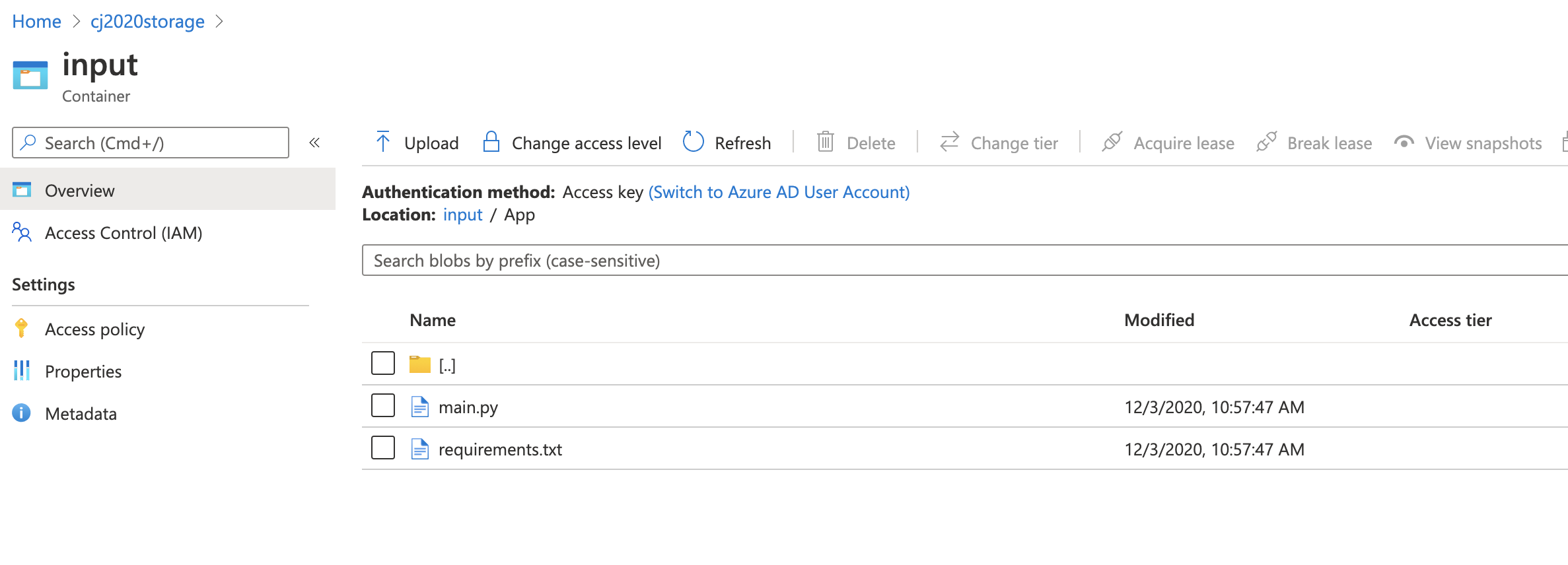
Inputs to Batch. Both the data InputFiles and code App will be uploaded to the linked Azure Storage.
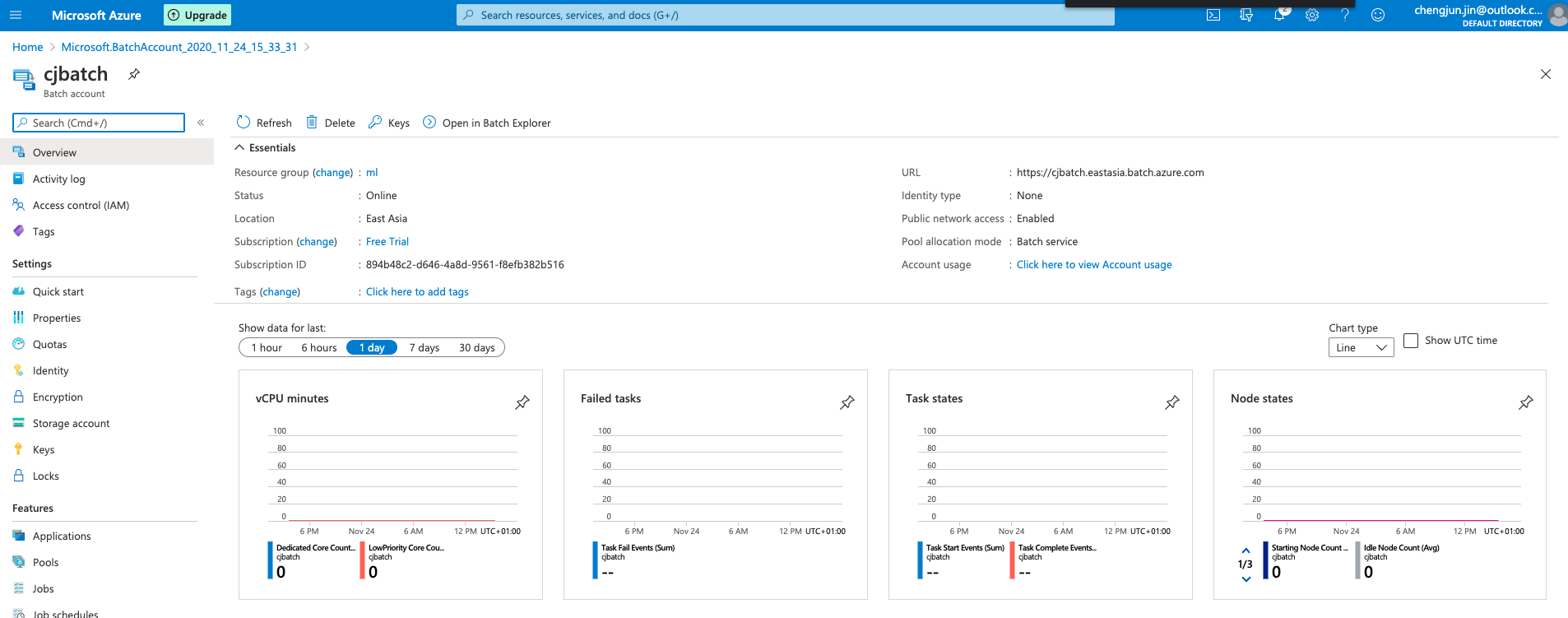
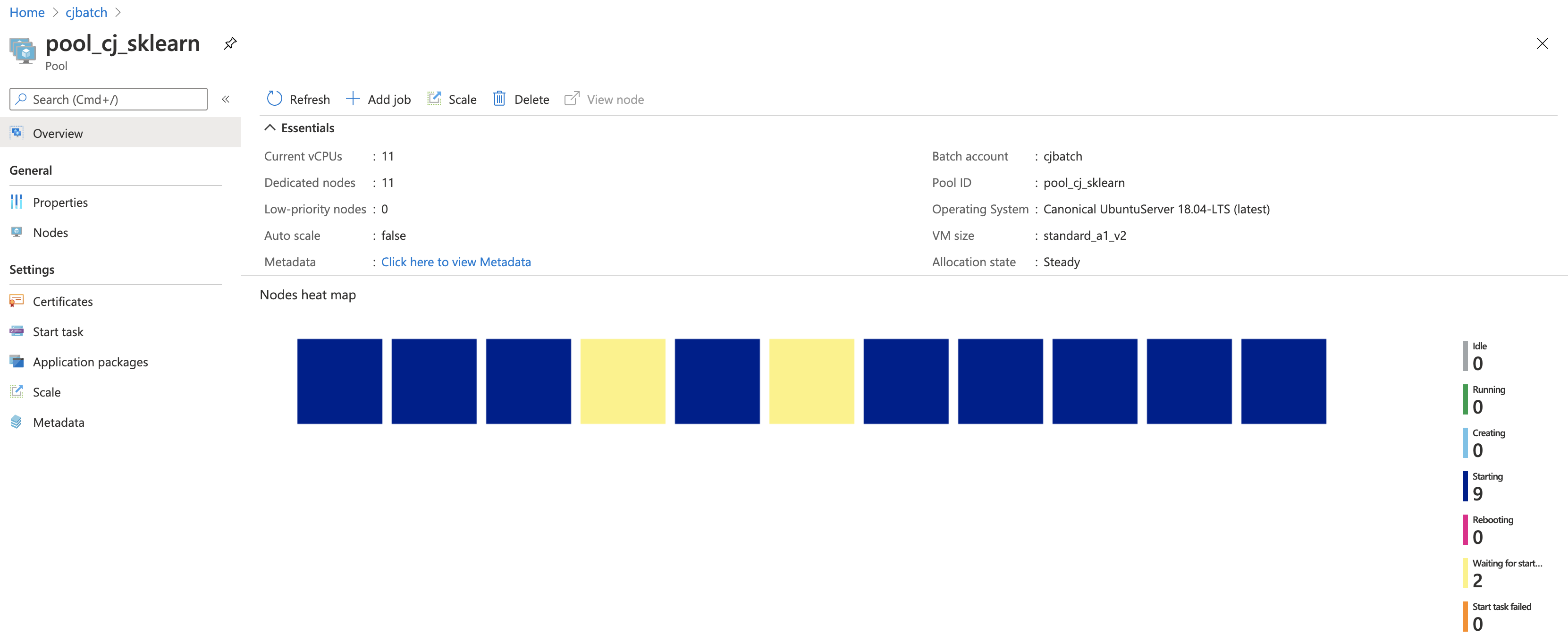
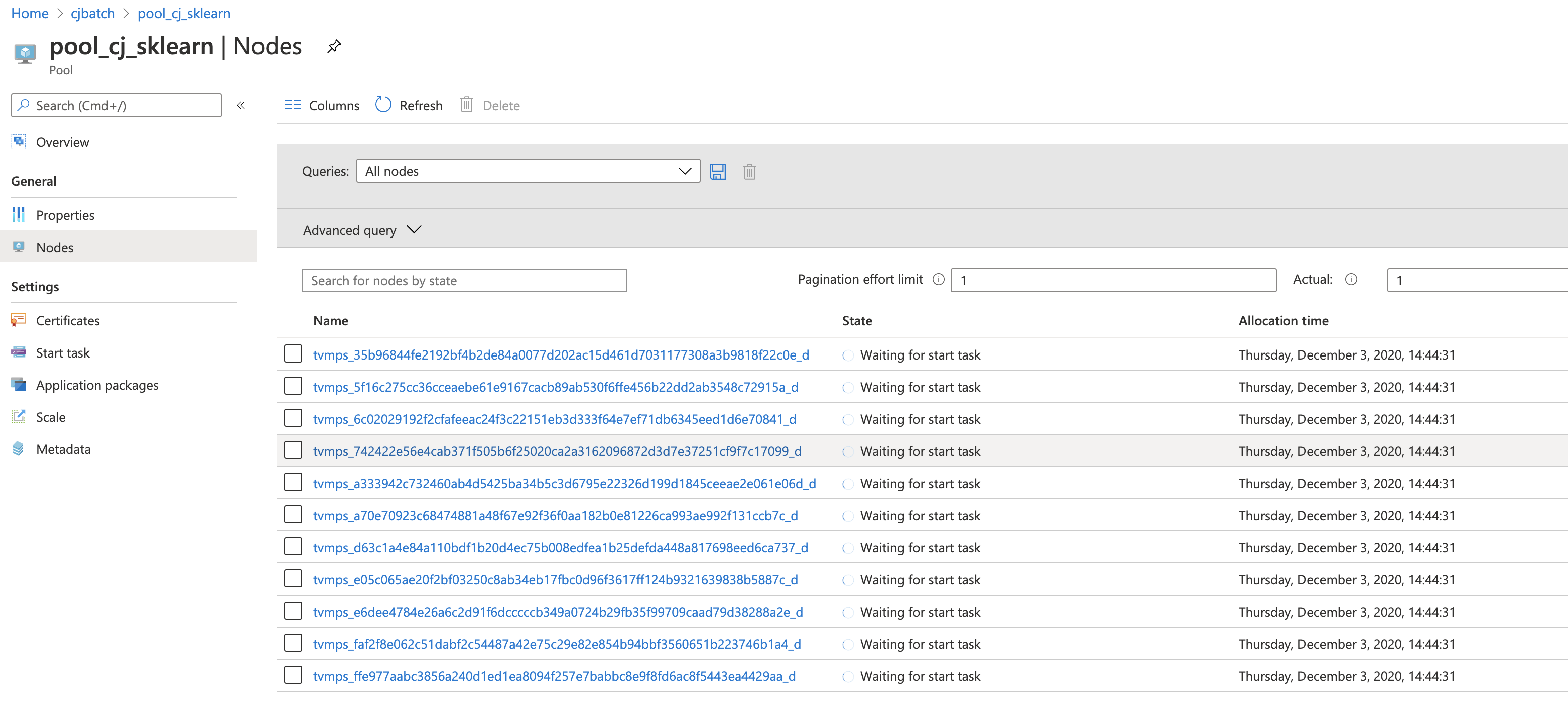
Pool creation. Once the pool is created, you can check the status of the pool and the nodes information.
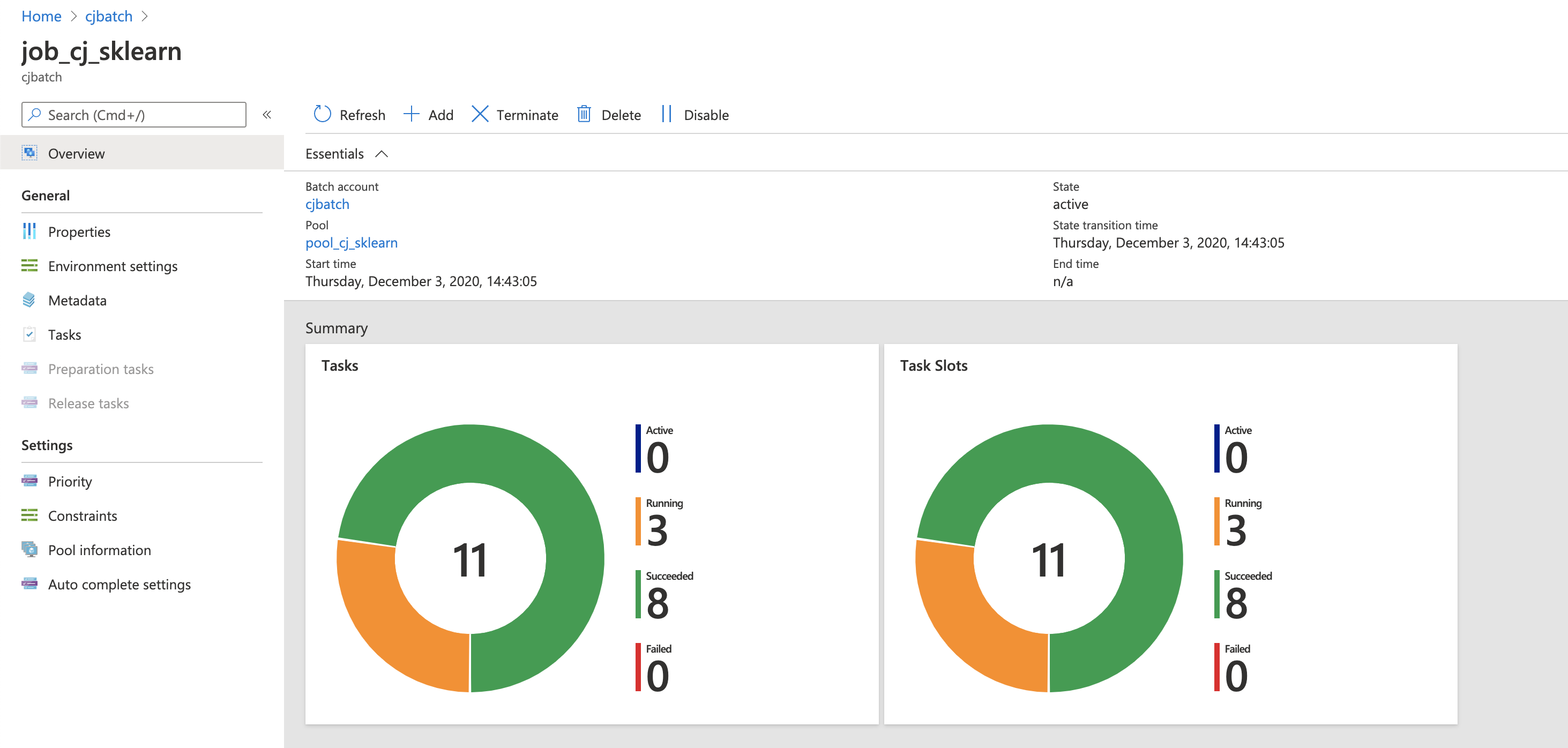
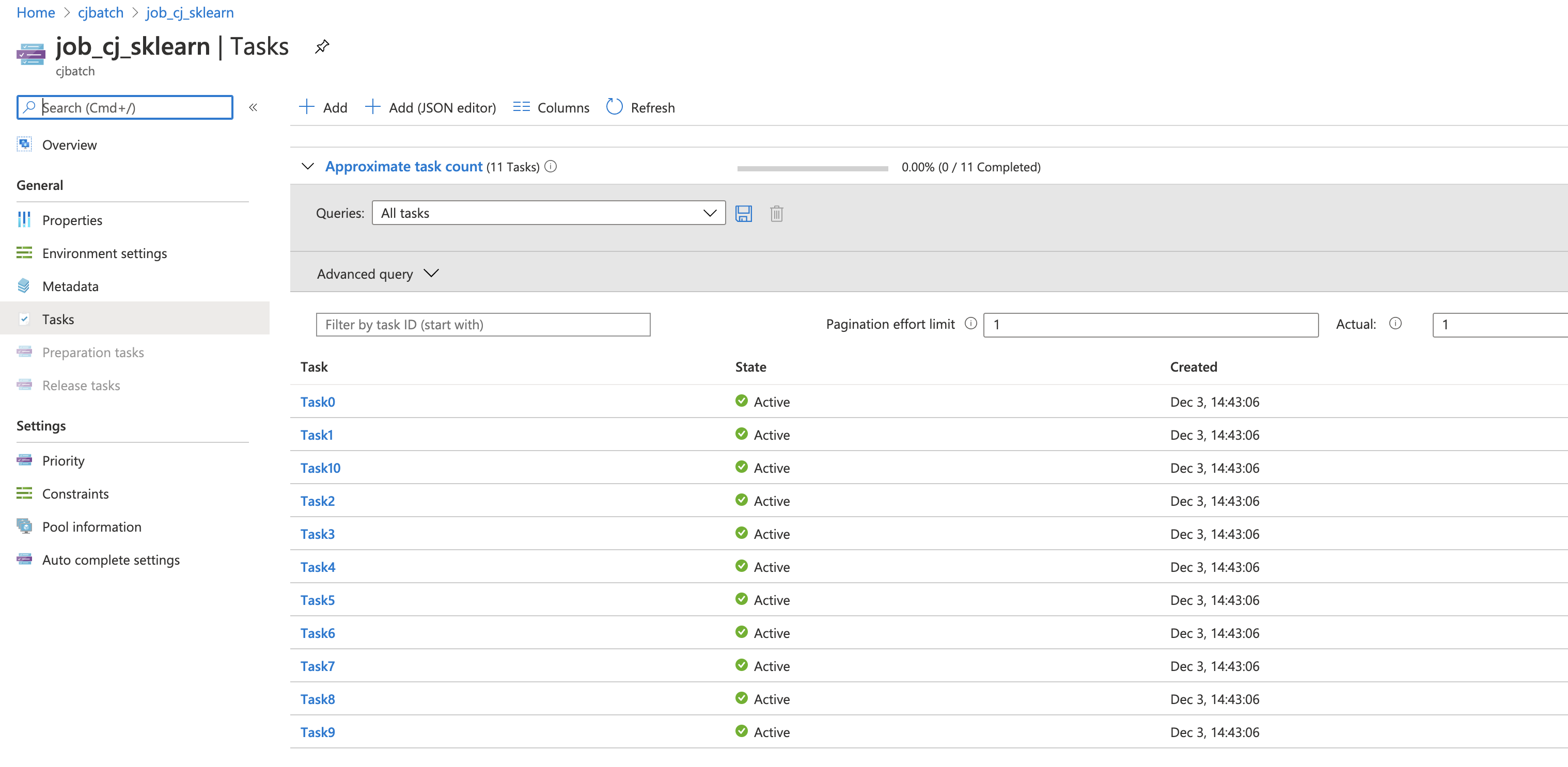
Job creation. Once the job is created, you can check the status of the job and the tasks.
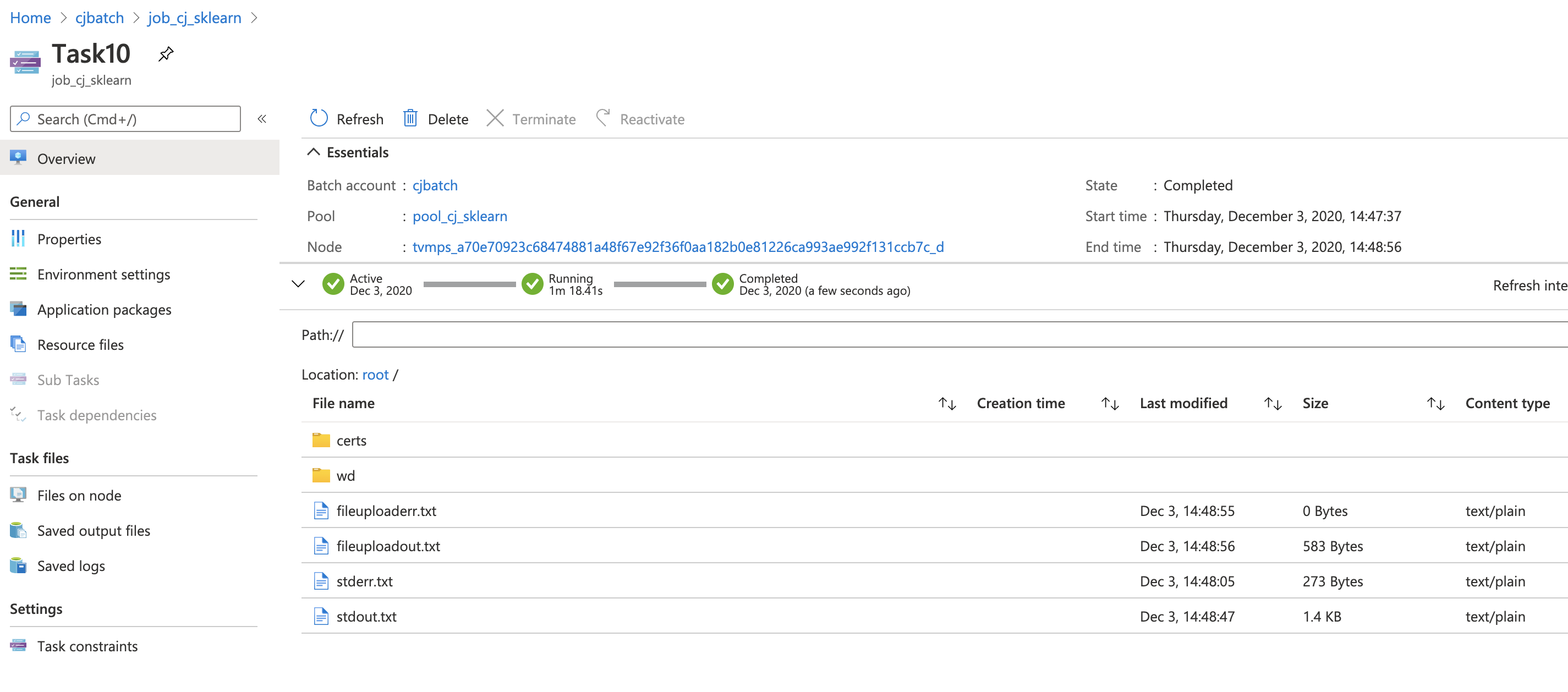
For each task, the outputs contains stderr.txt and stdout.txt.
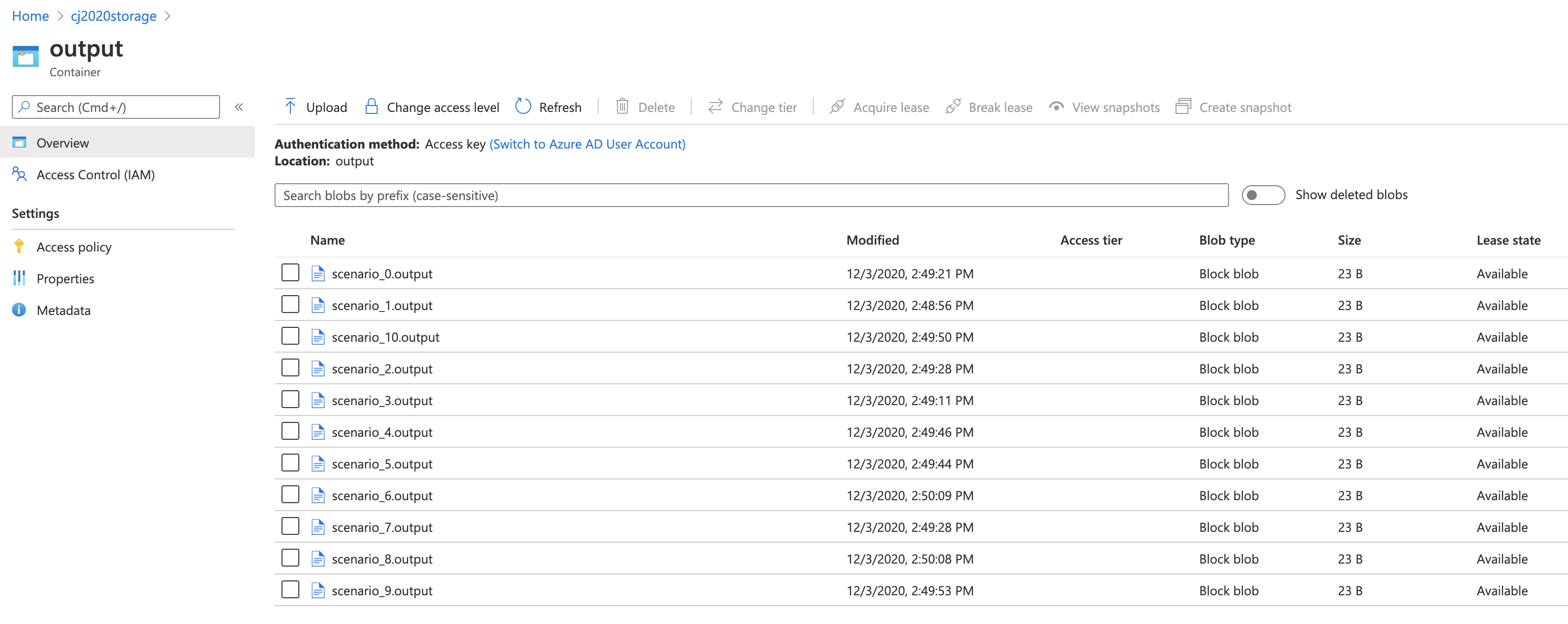
Outputs from Batch.
Summary
Choosing Azure compute platforms for container-based applications

Azure Container Instance vs AKS vs Azure Batch
Why Azure batch is recommened over Azure Container Instances and AKS for batch jobs?
One opinion: https://www.linkedin.com/pulse/machine-learning-containers-scale-azure-batch-kubernetes-josh-lane/
Azure Container Instances is a great solution for any scenario that can operate in isolated containers, including simple applications, task automation, and build jobs. For scenarios where you need full container orchestration, including service discovery across multiple containers, automatic scaling, and coordinated application upgrades, we recommend Azure Kubernetes Service (AKS).
- Use Azure Container Instances to run serverless Docker containers in Azure with simplicity and speed.
- Deploy to a container instance on-demand when you develop cloud-native apps and you want to switch seamlessly from local development to cloud deployment.