Distributed Automated-Machine Learning Framework
With the democratization of machine learning techniques and frameworks, many industrial use cases are utilizing data to drive the business values. For instance, demand forecast is one of the most popular applications in the retail space.
In contrast to academical research projects where novel algorithms are targeted, use cases in the industry lay more emphasis on the robustness and scalability. Moreover due to certain constraints in the business process, in addition to the model accuracy, other business KPIs will also be tracked and measured. Additionally, there is a clear pattern in applying machine learning models to business problems.
Therefore a distributed automated-machine learning framework will be beneficial, not only for quickly testing minimal viable product (MVP), but also for building a solid ground to scale up in the future.
The purpose of this blog is to describe the nuts and bolts of a home-made AutoML framework.
What’s machine learning
Data scientist’s view. From a machine learning theoretical point-of-view,
machine learning is divided into training and prediction phases.
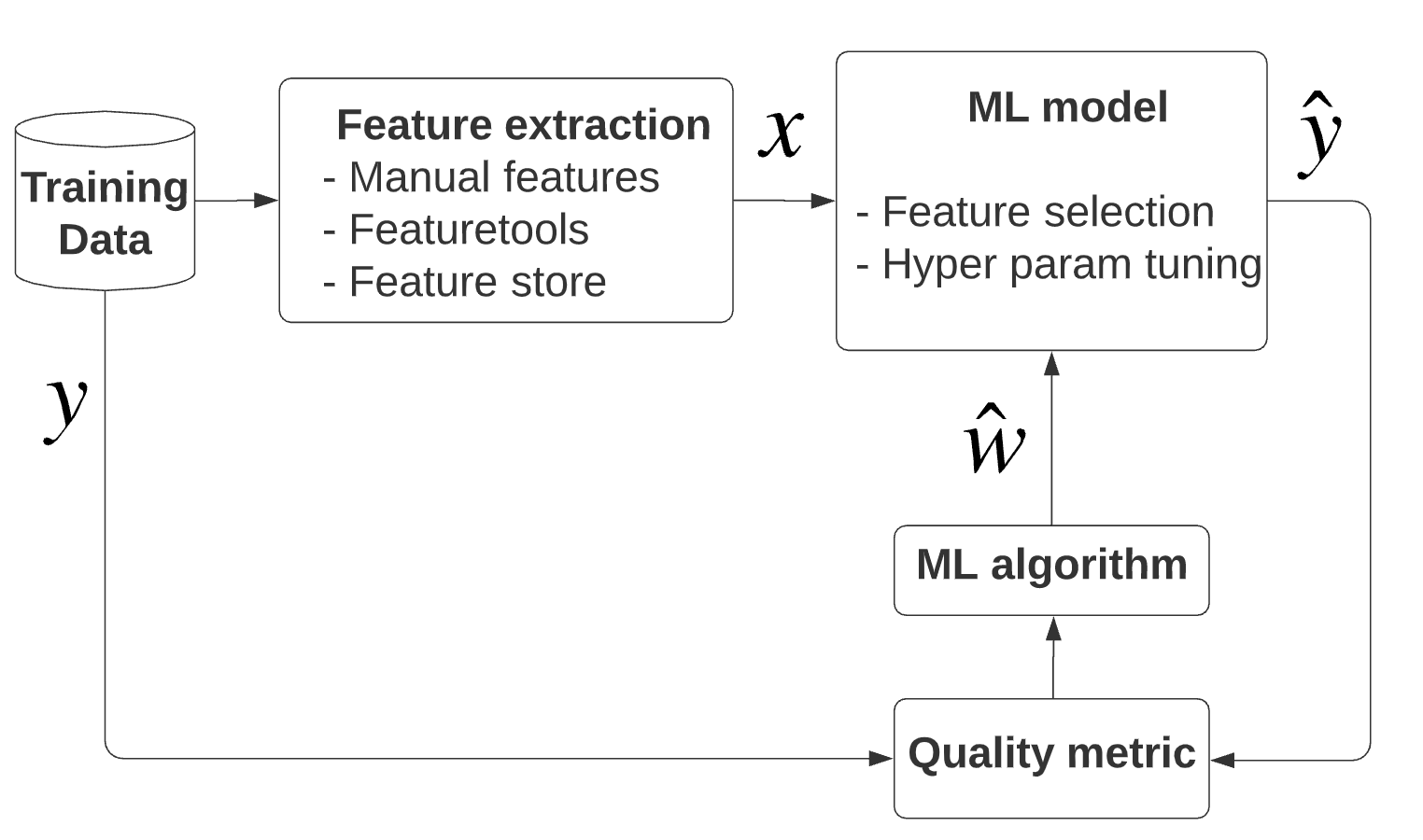
In the training phase, roughly speaking, we will have:
- Fetch the raw training data
- Feature extraction on the raw training data
- Pick up a model, a model quality metric, an optimization algorithm
- Then train the model iteratively
In the prediction phase,
- The testing data goes through the identical transformation
- Then apply the trained-model to the testing data
Software engineer’s view. From a real-world application point-of-view, a machine learning product should contain the following components according to Google.
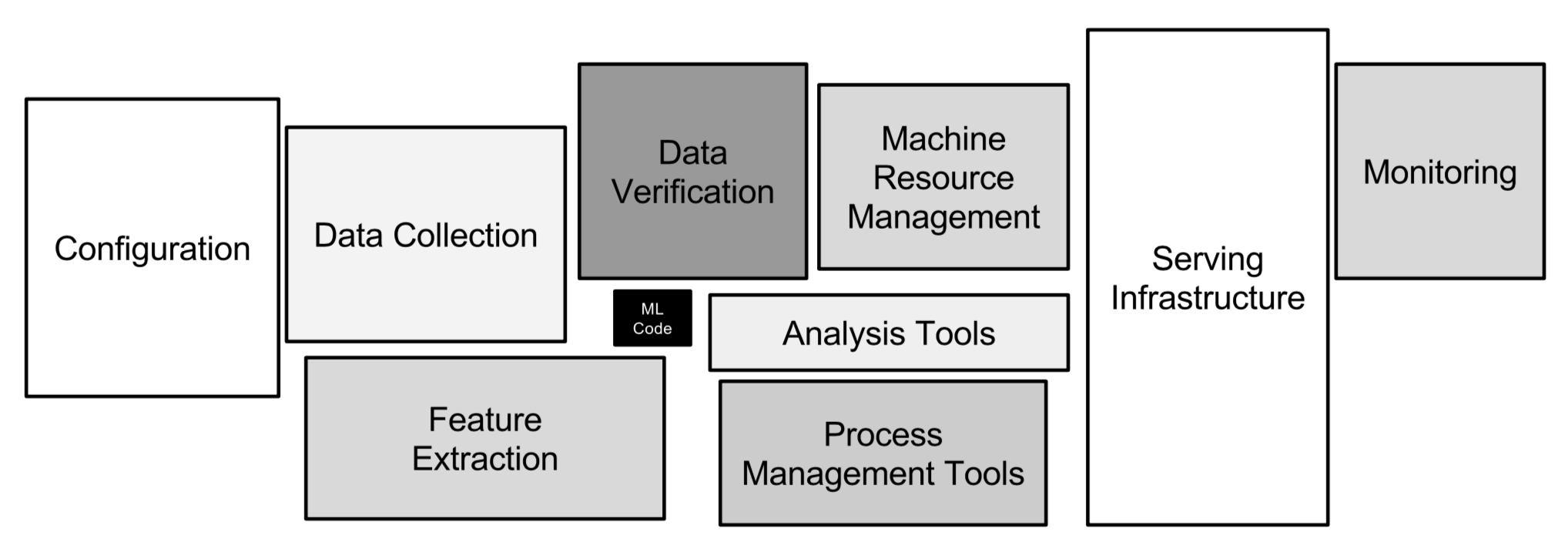
Data flow
For use cases where the data flow in terms of size manifests the pattern
below, we can apply spark to fetch the data of all the scenarios, and then split
into each scenario-level data where we apply python to process the model training step.
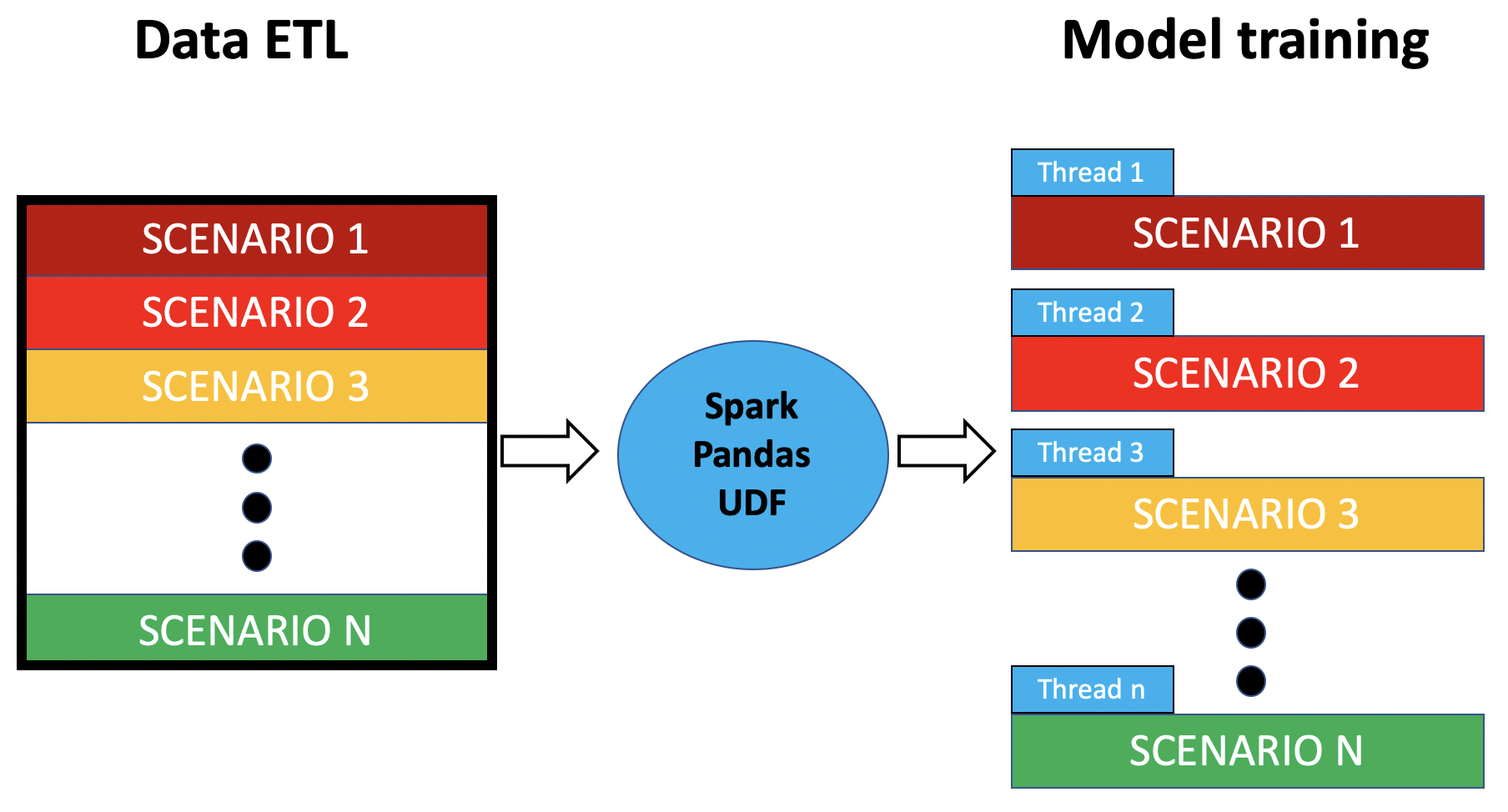
The two main reasons to use python for model training step:
- The size of scenario-level data can be fit into memory.
- Many handy libraries only have python API.
Data object
Data object consolidates different DataStreams and outputs the master_df
for training and prediction in the PySpark.DataFrame format. The master_df is considered as the raw training data set. Additionally, at this stage, master_df can be cached for data versioning and re-usability.
Note: The data ETL is written in Spark and no Spark action will be triggered here.
class Data:
def __init__(self, Config, SparkIO, is_train=True):
pass
def _append_streams(self):
self._streams = DataStreams()
for stream_name, stream in self._streams.streams.items()
setattr(self, stream_name, stream)
def _prepare_training_master_df(self):
df_stream_name_1 = self.stream_name_1.df
df_stream_name_2 = self.stream_name_2.df
df = apply_transformations(df_stream_name_1, df_stream_name_2)
return df
def _prepare_prediction_master_df(self):
pass
def master_df(self):
if self.is_train:
master_df = self.prepare_training_master_df
else:
master_df = self.prepare_prediction_master_df
def save_master_df(self):
pass
Spark Pandas UDF
The codebase contains both python and pyspark code, where they are
organically joined via spark pandas UDF. More details about Pandas UDF.

Moreover the spark pandas UDF provides a simple way to handle the embarrassingly parallelization – each model scenarios will be parallelized over a thread/slot/core in a single spark cluster.
Training phase. Once the master_df in PySpark.DataFrame format is prepared, we apply the Pandas UDF train to every scenario. The output will be a Pandas DataFrame, where each row contains model metrics for a model.
result_schema = StructType([
StructField("mse", FloatType())
StructField("r2", FloatType())
])
def train(df: pd.DataFrame) -> pd.DataFrame:
pipeline = Pipeline(is_train=True)
metrics = pipeline.run()
return metrics
master_df = Data(is_train=True).master_df
results = master_df.groupby("scenario_id") \
.applyInPandas(train, schema=result_schema)
results.count()
Prediction phase. Similar to Pandas UDF train, but the Pandas UDF
predict required is_train=False. The remaining difference resides in the Pipeline class. The output contains the predicted value for every sample.
result_schema = StructType([
StructField("sample_id", StringType())
StructField("predicted_value", FloatType())
])
def predict(df: pd.DataFrame) -> pd.DataFrame:
pipeline = Pipeline(is_train=False)
predictions = pipeline.run()
return predictions
master_df = Data(is_train=False).master_df
predictions = master_df.groupby("scenario_id") \
.applyInPandas(predict, schema=result_schema)
predictions.count()
Pipeline object
The data input to the
Pipelineis apandas.DataFramefor each scenario.
Training phase. The Pipeline will do the followings:
_prapare_pdata: Split the training data into training, validation, testing etc. Importantly thefeaturetoolsis used here to enrich the raw training table. Details in theTrainPredictDataclass._select_features: Different methods to select the best features. Details in theFeatureSelectionclass._tune_hyperparams: Different methods to do hyper-parameter tuning. Details in theHyperParamclass._get_model_metrics: All the model metrics are calculated. Details in theMetricclass._log_pipeline: Usemlflowto log the model, metrics, meta-data etc.
Prediction phase. The Pipeline will fetch the prediction data set, load
the trained model, and do the prediction.
from sklearn.pipeline import make_pipeline
class Pipeline:
def __init__(self, pdf: pd.DataFrame, is_train=True):
self.pdata = pdf
def _make_pipeline(self):
model = RandomForestRegressor()
imputer = SimpleImputer()
encoder = OneHotEncoder()
self.pipeline = make_pipeline(imputer, encoder, model)
def _prapare_pdata(self):
self.pdata = TrainPredictData(self.pdata)
def _select_features(self):
self.features = FeatureSelection()
def _tune_hyperparams(self):
self.best_pipeline = HyperParam()
def _get_model_metrics(self):
self.metrics = Metric()
def _log_pipeline(self):
# mlflow code
pass
def _predict(self):
pass
def run(self):
if self.is_train:
self._prepare_pdata()
self._make_pipeline()
self._select_features()
self._tune_hyperparams()
self._get_model_metrics()
self._log_pipeline()
else:
self._prepare_pdata()
self._predict()
How to debug code
Note: it only makes sense to do a run with one scenario.
In this framework, we can put a breakpoint anywhere in the codebase, like:
import ipdb; ipdb.set_trace()
Then we can trigger the debugging with code change below in run_train.py:
train_df = data.master_df.toPandas()
results = train(train_df)
If you are using the spark cluster from cloud providers, you can use
dbconnect to establish the connection and execute the computation on the remote spark cluster details.
Practicality
Spark cluster. Depending on your application, you need to integrate with your own Spark cluster setting. Most cloud platforms provide managed spark cluster service. For instance, Azure provides Azure Databricks and HDinsights.
Azure Databricks provides on-demand spark cluster along with the Databricks
notebook environment. In such case, the pandas UDF in the format of .py
can be imported to Databricks notebook, either manually or by Databricks
API.
Additionally the Databricks notebook can be easily scheduled with
alerts.
MLFlow is an open source project by Databricks. If you are using Databricks with Azure or AWS, the Databricks workspace has integration with the MLFlow, along with the Model registry for model deployment. Otherwise you can set up the MLFlow tracking server yourself.
Summary
I have discussed the building blocks in this home-made machine learning framework. There are a few ingredients I have not touched on
- Data versioning
- Logging and monitoring solution
- Model management solution
- Feature store
- CI/CD with Azure DevOps
In the coming blogs, I will discuss each topic in details.